-
2018年6月、KYOTO Design Labはシンガポール工科デザイン大学[SUTD]と共同で、SNSの地理情報分析とビジュアライゼーションを通した都市リサーチワークショップ「Decoding Data Landscapes」を開催した。日々蓄積されていく大規模なデータを都市空間へ活用するためには、どのような理論と方法が求められるのだろうか。ワークショップに参加した、京都工芸繊維大学大学院生の岡田隆太朗によるレポートをお届けする。

WS最終プレゼンテーションの様子
Text and Visual: Ryutaro Okada
Photo: Tomomi Takano
ビッグデータという言葉が市民権を得てひさしい。情報処理技術の発達を背景に、これまで扱いかねていた膨大な量のデータが活用できるようになった。今やビッグデータは医療、エンジニアリング、政治、マーケティングと、あらゆる分野において新たな視点や戦略を提供しつづけている。
では、都市という強大な情報の塊をビッグデータの視点で解析すれば、そこにはどのような発見が生まれるだろうか?
シンガポール工科デザイン大学[SUTD]のサム・コンラッド・ジョイス助教を講師に招き開催された「Decoding Date Landscapes」は、SNSの地理情報を活用し、都市がもつ文脈のビジュアル化を学ぶワークショップである。開催期間は2018年6月25日-28日のわずか4日間。超短期間のスケジュールで行われた本ワークショップだが、プログラミングの初級者・中級者を対象に、基礎からデータ分析まで取り扱うというから驚きだ。
以下、4日間におよぶワークショップの内容をお届けしたい。
ビッグデータをビジュアライズするためのプログラミング
ワークショップ初日。会場には国籍も専攻もスキルもさまざまな参加者たちが集まっていた。学生のみならず社会人も参加していて、ワークショップの注目度がうかがえる。自己紹介もそこそこに、参加者たちにはAnaconda(プログラミング環境構築ソフトウェア)、サンプルコード、そしてワークショップの素材となる膨大なTwitterのcsvデータが配布された。
この日の残り時間は、参加者の大半を占めるプログラミング未経験者のためのPython講座に費やされた。Pythonは近年注目を集めているプログラミング言語の一種で、今回のワークショップで用いられるもっとも重要なツールである。シンプルな文法と豊富なライブラリによって手軽に多彩なプログラムを構築できるPythonは、初心者にも覚えやすいと多くの支持を集めている。
この日レクチャーされたのは変数・リスト・for文といったPython基礎中の基礎。今回のワークショップで重視されるのは、発展的なプログラミングの文法知識よりも、入門書レベルの知識を組み合わせる理解力と応用力だった。
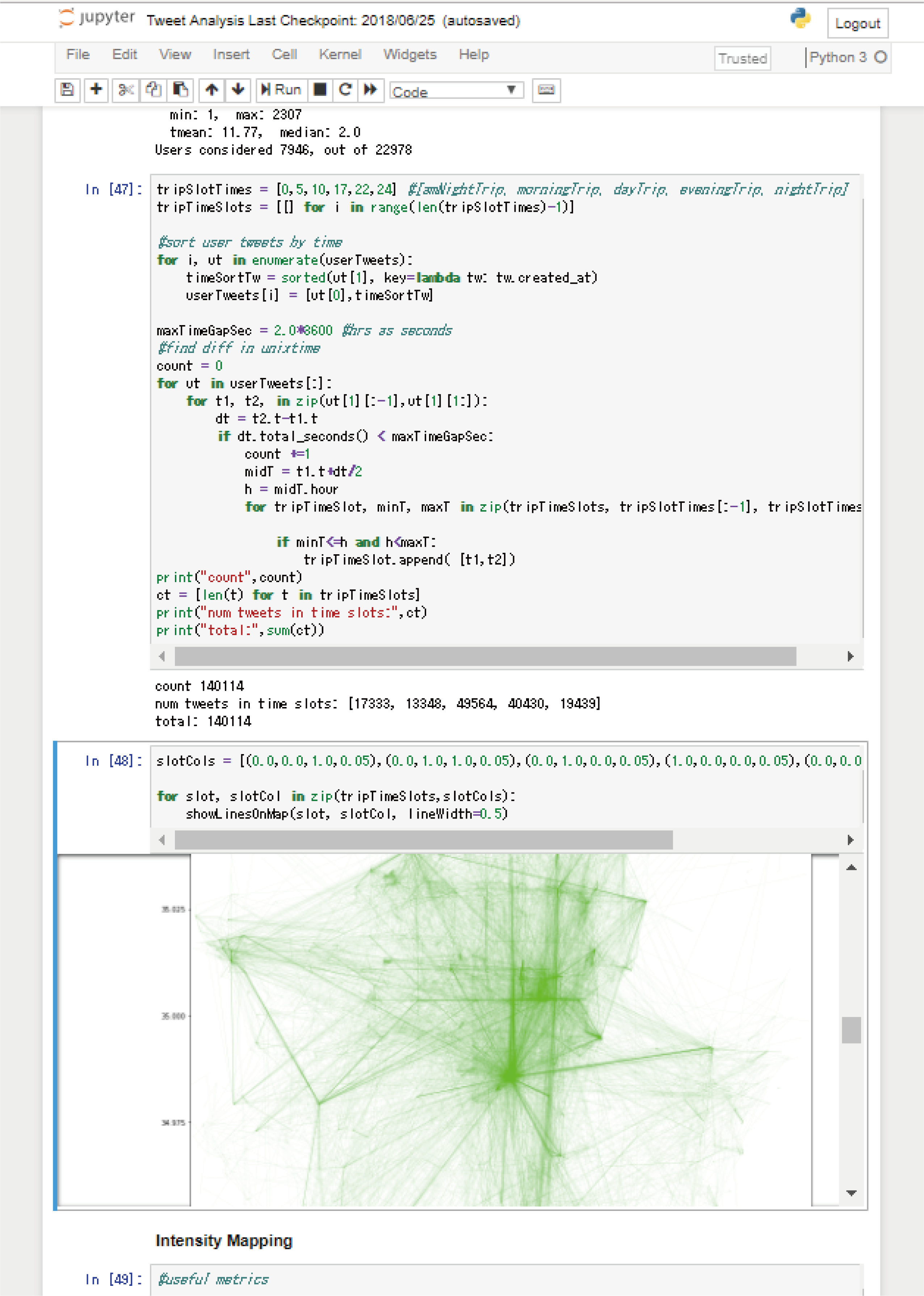
配布されたサンプルコード
ワークショップ2日目は、初日に配布されたサンプルコードを各自理解することに時間が割かれた。
膨大なデータをどのように分類・抽出・整理するかを司るコードは、データをビジュアライズするうえでもっとも重要な部分だ。ここが理解できなければどんなに優れたアイデアでも実現することはおぼつかない。あるものは一心不乱に黙々とコードを読み、あるものは隣の席の初対面の参加者と意見を交わしあい、あるものは講師のジョイス氏に教えを請い、コードの理解に努めた。
複雑に絡み合ったコードの関係性も、じっくり読めば次第にその構造が見えてくる。たった4日でプログラムが組めるのかと不安だった未経験者たちの緊張も、コードの仕組みが見えるに連れ氷解していった。
データを「見る」ことの困難
いよいよ本格的に都市解析をおこなう3日目だ。参加者たちはチームにわかれ、アイデアを出しあい、コードを書き始めた。
配布された京都市内の11年分のツイートには、各ツイートの送信時刻や位置情報データが匿名でまとめられている。これを使えば京都という都市の新たな側面をいくらでも分析できる気さえしてくるほど、データ量は膨大だった。ただし、データ分析の難しさはここからだ。
たとえば「雨」「晴」という単語に注目して、都市と天候の間にある隠れた関係を見つけようと試みたとしよう。Pythonを使えば、「雨」や「晴」という単語を含むツイートが、京都のどこでよくつぶやかれているのかを抽出することはそれほど難しいことではない。
しかし、技術的には容易でも、この切り口で京都と気象が持つ新たな側面を見つけるとなると話は別になる。というのも、「雨」という単語を含むツイートのほとんどは、京都駅と四条通り一帯に集中しているからだ。

2012年につぶやかれた「雨」という漢字を含むツイートの分布
言うまでもなく、この2箇所は天候によらず、そもそも人口が集中する場所だ。だから京都駅で多く「雨」とつぶやかれていることからは、「京都駅には人がたくさんいる」以上の意味を見出すことが難しい。
また、意図しないツイートを拾い上げてしまい、誤った分析結果が表示される可能性にも、注意しなければならない。図3は「晴」という単語を含むツイートを抜き出し地図上に配置したものだ。京都駅や四条のほか、晴明神社にもツイートが集中している。しかしこれをみて「天気のいい日は晴明神社に人が集まる」と結論付ける人はいないだろう。晴明神社に含まれる「晴」という漢字と、気象用語としての「晴」をプログラムで区別することは困難なのだ。この種の落とし穴は、ビッグデータを分析する上で細心の注意が必要である。

2012年につぶやかれた「晴」という単語を含むツイートの分布
このように、膨大なデータがあることと、そこから意味を見い出せるかはまったく別のことだ。そしてその切り口を見つるために、このワークショップではグループディスカッションを重視している。デザイン、歴史、経済、景観、情報、さまざまな分野の知識がPythonを媒体としたコミュニケーションによって融合し、化学反応を起こせるか。それがこのワークショップの鍵となる。
その一例として、都市史研究の視点とTwitterのデータ分析を組み合わせた、都市の空間イメージに関する考察を進めてみよう。
Twitterから見える都市のイメージ
観光都市である京都には、年間を通じて多くの観光客が訪れる。中でも桜の季節には、京都市内に点在する桜の名所は一層の賑わいを見せる。古来より京の桜は、ときには歌に詠まれることで、ときには絵図に描かれることで、ときには物語の舞台となることで、全国的な知名度とブランドを獲得してきた。そして今日でも、桜に彩られた京都という都市イメージが、Twitterにつぶやかれることで定着されていく。
では、詩歌や絵画から各時代の風景を読み取るように、Twitterに眠る無数の桜ツイートから、現代の京都という都市の側面を浮き彫りにできるのではないだろうか。
–
次の図は、2013年につぶやかれたツイートのうち、「桜」という単語を含むものを抽出し、京都市の地図上にマッピングしたものである。
普段から人口密度の多い京都駅と四条以外にも、清水寺、東寺、二条城、京都御所など、近代以前から桜の名所として知られる施設は多くの桜ツイートを獲得している事がわかる。また、明治維新後に桜が植えられた円山公園(明治20年)や平安神宮(明治28年)、あるいは木屋町通(昭和25年)、祇園白川(昭和25年)などの戦後に植樹された場所も、他の名所に負けない人気を誇っている。
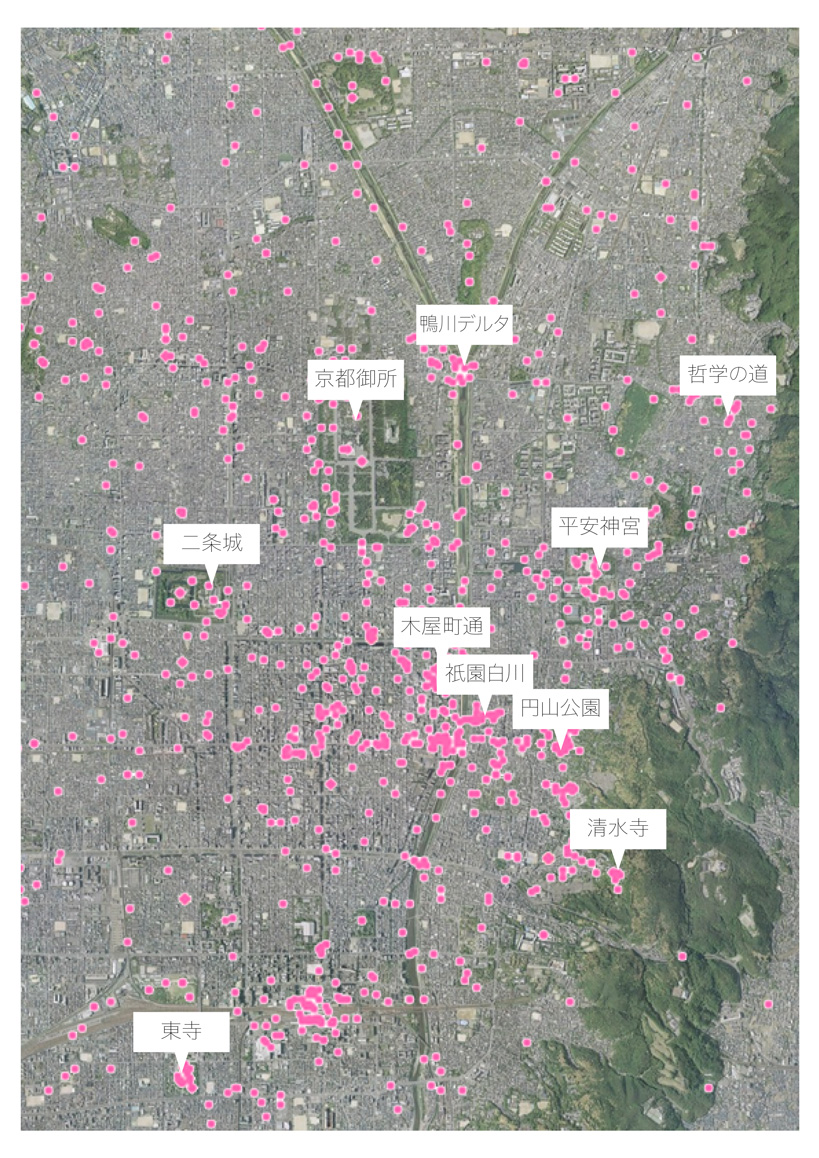
京都市街地周辺の「桜」という漢字を含むツイートの分布。背景画像は地理院地図(https://maps.gis.go.jp)より。
他方で、同じく近代以後に桜が植えられた場所であっても、蹴上インクライン(明治24年)・加茂川沿い(明治35年)・鴨川沿い(大正4年)の桜ツイートはさほど集中していない。疏水分線沿い(昭和7年)・高野川沿い(昭和25年)・高瀬川沿い(昭和25年)・夷川船溜まり(昭和47年)など昭和期に植樹された大量のソメイヨシノ並木も、前述の木屋町通と哲学の道を除けばその密度は低い。北山の京都府立植物園(大正4年)は歴史も古く、京都でもっとも多くの種類の桜を楽しめる場所だが、やはりツイートされるには至らないようだ。
このように見てみると、一口に「京都の桜」と言えど、そのツイートされる頻度は一様ではない事がわかるだろう。
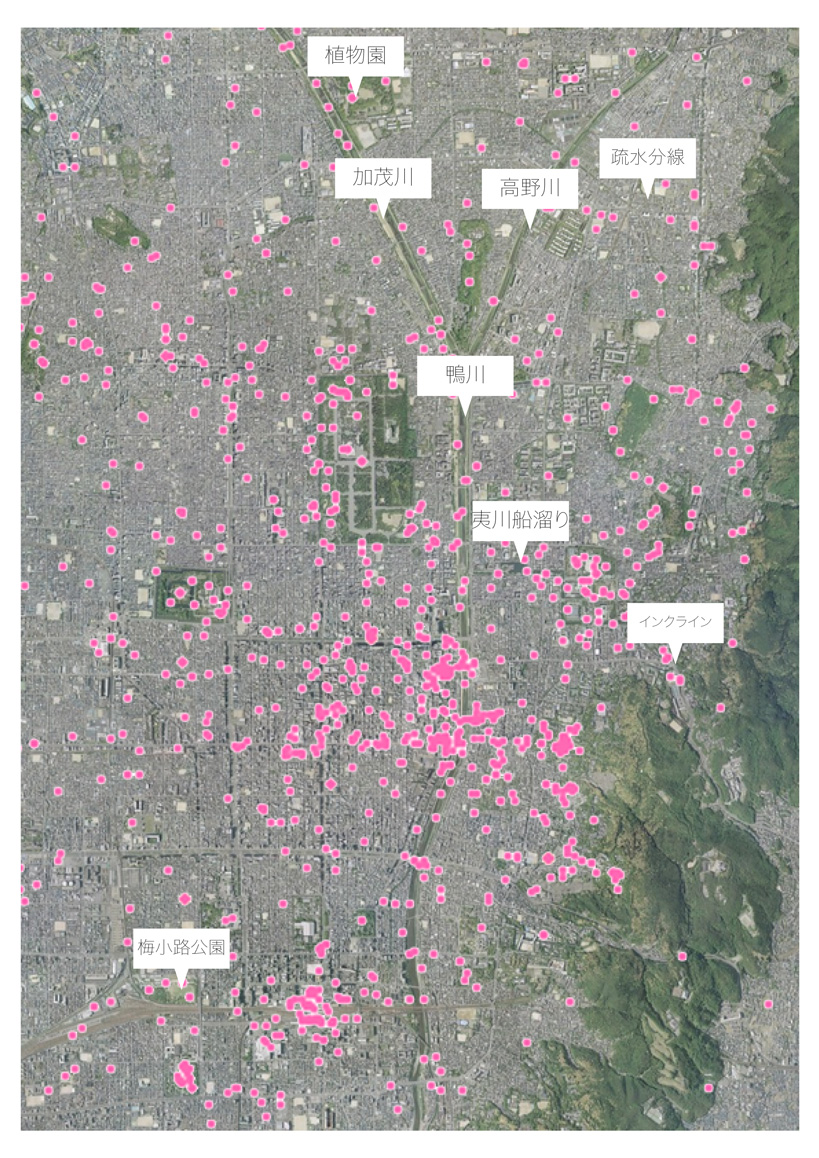
京都市街地の桜が植樹されているが、「桜」を含むツイートが少ない場所
ではその違いはどこから来るのだろう? 少なくとも、物理的に桜が咲いていることは、その桜がツイートされやすいことの直接の要因たり得ていない。それどころか、桜の樹植時期が古いことや、桜の咲く量や種類でさえ、ツイートされることの十分条件ではない。
一方で木屋町通や祇園白川のように、古都京都の風情に合致する伝統的なイメージが定着している場所であれば、その成立が戦後であったとしてもSNSを経由して人々に発信させる魅力を持つ。
どうやら人びとは、桜が美しいという理由以上に、その場所の桜が、広告・出版物・webメディアで取り上げられてきた「京都らしい風景」に合致する場所を求めているようだ。
詩歌の世界では、「恋の障害」といえば「逢坂山」、「紅葉」なら「竜田川」のように空間とイメージが一体となっている事例は非常に多い。
このように古来より日本人は、実際に名所を訪れ鑑賞することよりも、叙景詩や風景画で描かれた「その名所らしい風景・イメージ」を愛でることを重視してきたという。地図上にマッピングされた桜ツイートの多寡は、こうした日本人の名所好きが「SNS映え」という形で現代に引き継がれていることを示唆しているのかもしれない。
–
ただ抽出された桜ツイートのデータをながめているだけでは見えなかった京都の側面が、ツイートされた場所の歴史やイメージといった都市史的な視点を導入することで浮き彫りになる。今回のワークショップでは、このようなデータへのさまざまなまなざしを、グループディスカッションを通したいくつものアイデアとして検討することができた。
どのようなアプローチでデータを整理するかという発想と、そのアイデアをいかにして実現するかという技術上の課題。その両者をいかに結び付けられるか? この一連の取り組みこそ、このワークショップ最大の課題である。
ワークショップも折り返し地点に入り、参加者たちのディスカッションはこれまでにも増して熱を帯びた。
都市はつぶやく
ワークショップ最終日。参加者の出したアイデアは驚くほど多岐に及んだ。
祇園祭と山鉾に関するツイートの追跡、より多くの人からリプライを集めるアカウントの居場所の解析、観光地の12ヶ月ごとの人々の集まりの変化、京都在住デザイナーの遷移分析など、様々な切り口で京都という都市の新たな側面を読み解く試みが模索された。分析結果を表現する方法も、グラフやプロット、メッシュと多彩である。CADソフトRhinocerosと組み合わせ、情報を立体データに加工し、結果を3Dプリンターで出力したチームさえあった。
一次情報としてTwitterを使うことによって、どんな綿密な統計調査も行政文書も明らかにし得なかった都市の一面を垣間見ることができたのだ。

最終プレゼンテーションの様子。Grasshopperを用いた分析データの立体化を試みている

サム・コンラッド・ジョイス助教[SUTD]。Buro Happoldにてデザインシステム・アナリストを務め、プロジェクトのジオメトリー・構造・基本計画に携わったのち、Foster+PartnersのR&Dグループを率いた
本プロジェクトは、単なる短期間集中プログラミング学習コースではない。前述の通り、全4日間の日程のうち、Pythonの学習に当てられたのは実質前半の2日間にとどまる。このワークショップの本番は後半の2日間、アイデアを出し、コードとして実装するまでの、仲間とのコミュニケーションにあるのだ。
ビッグデータの導入が遅れていると言われる建築・都市デザインの領域に新しい時代が訪れたことを予感させる、そんな4日間であった。
ライター紹介: 岡田隆太朗
1994年生まれ。京都工芸繊維大学大学院 建築学専攻 都市史研究室所属。日本の近代都市史研究を中心軸としつつ、書籍編集・リブランディング・建築設計を学ぶ。
Edited by Kouhei Haruguchi
KYOTO Design Lab × SUTD
Decoding Data Landscapes
都市はつぶやく
──ビッグデータ活用による京都の都市解析
日程|2018年6月25日[月]-28日[木]
場所|京都工芸繊維大学KYOTO Design Lab
ワークショップリーダー
Singapore University of Technology and Design [SUTD]
サム・コンラッド・ジョイス 助教
–
KYOTO Design Lab
大田省一 准教授
赤松加寿江 講師
Coming soon…